連続音声からの場所名の獲得

研究概要
ロボットを様々な場所に連れて行き,その場所の名前を音声で教示していきます.ロボットは音声教示から場所を表す音素系列とその意味を獲得することができます.
背景と目的
サービスロボットは,家庭やオフィスの場所の名前を知っておく必要があります.しかし,その知識を開発者が事前に与えることはできません.
そこで,この研究では,ユーザがロボットを連れて建物の中を案内し,音声で場所の名前を教えることで,それぞれの環境に合わせた場所の知識を学習できるアルゴリズムの実現を目指しています.
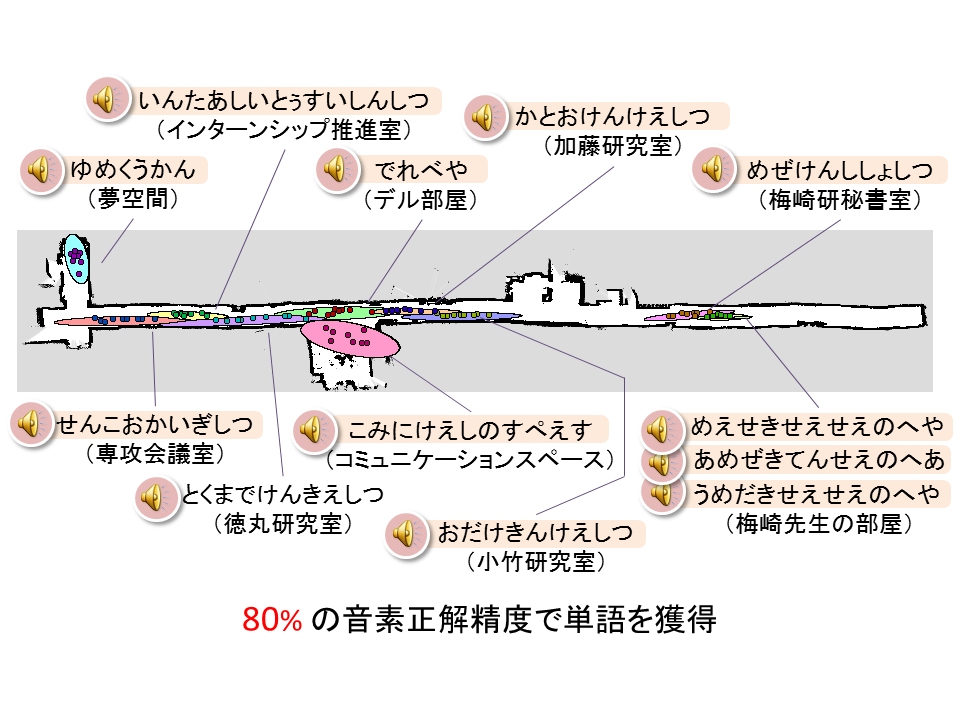
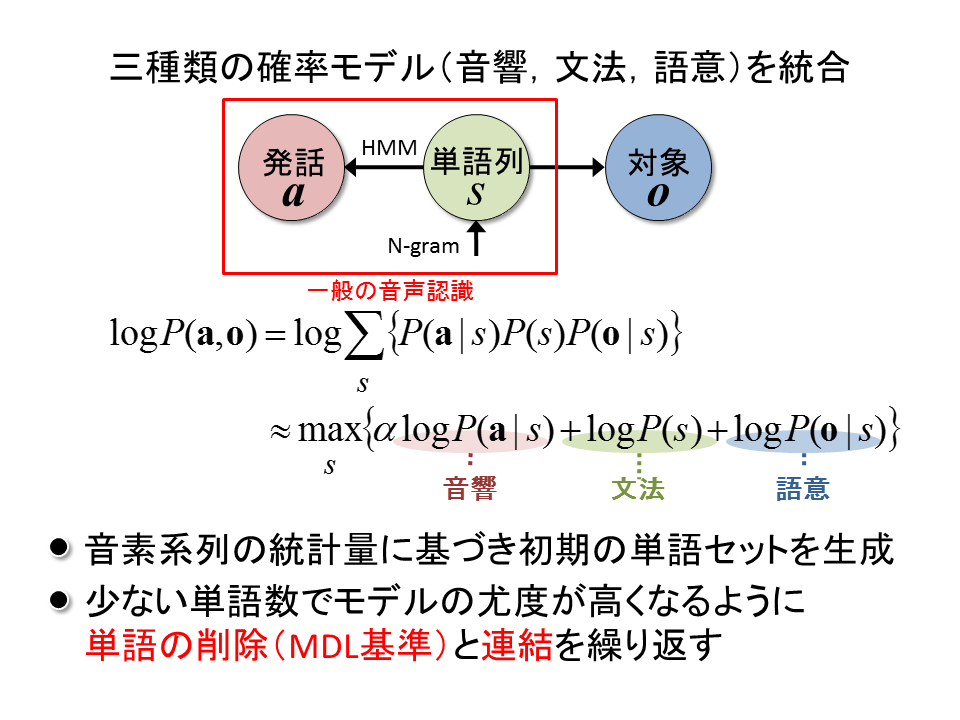
アプローチ
音響モデル(単語と音の関係),言語モデル(単語と単語の並び),意味モデル(単語と対象の関係)の3種類の確率モデルを統合し学習することで,意味のある単語を獲得することができます.
文献情報
-
Ryo Taguchi, Yuji Yamada, Koosuke Hattoki, Taizo Umezaki, Masahiro Hoguro, Naoto Iwahashi, Kotaro funakoshi, Mikio Nakano, "Learning Place-Names from Spoken Utterances and Localization Results by Mobile Robot," Proc. of INTERSPEECH2011, pp. 1325 - 1328, 2011.
-
田口亮,岩橋直人,船越孝太郎,中野幹夫,能勢隆,新田恒雄,「統計的モデル選択に基づいた連続音声からの語彙学習」,人工知能学会論文誌,25 ( 4 ) 5491 - 5501 2010年06月 [PDF]